
Finding Patterns That Only Match Registered Domains (and Which Don't "Overmatch" Against Subdomains)

Sometimes you may want to match domains that have a particular string followed by a top-level domain (TLD), but run into problems with “overmatching,” such as finding subdomains buried deep in domains that also match your pattern of interest. In this article, we’ll show you how to use Farsight DNSDB to find such a set of domains quickly.

A “cupcake” Example
As an example, assume you’re thinking of starting a retail cupcake company and want to check Farsight DNSDB to see what “cupcake” domains have already been registered (Figure 1). You might immediately think of using DNSDB Flexible Search to find these domains:
$ dnsdbflex --regex "cupcake" -l0 -A90d > cupcake.jsonlDecoding the preceding command:
dnsdbflex DNSDB CLI flexible search command
--regex we're choosing to make a regular expression search
"cupcake" the literal string we're searching for
-l0 dash ell zero means "return up to a million results"
-A90d limit hits to those that have been seen in the last 90 days
> cupcake.jsonl write our results to the specified fileWe can then check to see how many hits we’ve gotten with the Un*x wc -l command:
$ wc -l cupcake.jsonl
366603 cupcake.jsonl366,603 hits? That’s a lot of “cupcakes” to eat…er, results to review! Peeking inside, some of the entries look like
{"rrname":"mamasbabycupcakes.disco.ac.","rrtype":"A"}
{"rrname":"cupcakestakethecake.disco.ac.","rrtype":"A"}
{"rrname":"cupcakes-plain-and-fancy.disco.ac.","rrtype":"A"}
{"rrname":"cupcake.redbull.ac.","rrtype":"A"}
{"rrname":"cupcakes.redbull.ac.","rrtype":"A"}
[etc]While those results all happened to be “A” records, perhaps some of the results include “A” records as well as CNAME records, NS records, TXT records, etc. Let’s drop the RRtype and keep just unique RRnames:
$ jq -r '.rrname' < cupcake.jsonl | sort -u > cupcake-2.txt
$ wc -l cupcake-2.txt
297898 cupcake-2.txt297,898 is somewhat better than 366,603, but that’s only an 18.7% improvement on a percentage basis. Lots of the remaining names may actually be synthesized wildcards that really don’t have anything substantive to do with cupcakes.
Let’s filter our results a little further, keeping just “two-label domains” that mention “cupcake” somewhere in the two most significant labels. We’ll select two label domains by excluding any domains that contain two or more dots. We can do this using grep -v:
$ sed 's/\.$//' < cupcake-2.txt | grep -v "\..*\." | sort -u | grep cupcake > cupcake-3.txtDecoding the preceding command pipeline:
sed Un*x stream editor command
's/\.$//' delete any trailing periods
< cupcake-2.txt this means "take lines from this file as input"
| Pipe, send the output from the preceding command "into" the next command
grep Un*x search command
-v dash vee inverts the match; only keep lines that don’t match the pattern
"\..*\." match a literal period, any characters (or nothing), and a literal period
sort -u sort and keep unique input lines
grep cupcake ONLY keep lines that still mention the literal string "cupcake"
> cupcake-3.txt write the output to this new fileThat leaves us with a little over 14,000 domains:
$ wc -l cupcake-3.txt
14137 cupcake-3.txtFind Domains where “cupcake” is at the Start or End of the 2nd Label of an Effective 2nd-Level Domain
Sometimes you might only care about domains where a string is at the beginning or end of a specific label. We can pull matching hits by making a slightly more complicated query, pulling hits where cupcake is at either the beginning or end of a label:
$ dnsdbflex --regex "(\.cupcake\.*\.|\..*cupcake\.)" -l0 -A90d > cupcake-first-or-last.jsonl
$ wc -l cupcake-first-or-last.jsonl
47966 cupcake-first-or-last.jsonlThe key to this above query is the ‘regex’ component, the parenthesized alternative regular expression. Either of two patterns will match our regex:
- Find a literal dot followed by the string literal cupcake followed by anything (or nothing) and then another literal dot, OR
- Find a literal dot followed by anything (or nothing) followed by the string literal cupcake and then another literal dot
Now let’s trim the results so we only keep the effective top level domain plus one more label using 2nd-level-dom-large. See Appendix A for code which helps us do this.
$ jq -r '.rrname' < cupcake-first-or-last.jsonl | 2nd-level-dom-large | grep "cupcake" | sort -u > cupcake-e2ld.txt
$ wc -l cupcake-e2ld.txt
26274 cupcake-e2ld.txtInspecting those results, we quickly see a disproportionate number of “cupcake.is” domains: 23,800 out of 26,274 (90.58%) are from that domain. Is this a wildcard domain? Double checking, “cupcake.is” is listed in the “private domains” section of the Public Suffix List:

We can test and confirm that it is a wildcard domain since any arbitrary hostname part will resolve:
$ dig anything-at-all.cupcake.is
[...]
anything-at-all.cupcake.is. 1799 IN A 192.64.119.254We’ll exclude those domains, except for cupcake.is itself:
$ egrep -v "\.cupcake\.is$" cupcake-e2ld.txt > cupcake-e2ld-trimmed.txt
$ wc -l cupcake-e2ld-trimmed.txt
2477 cupcake-e2ld-trimmed.txtEnrich with DomainTools Domain Risk Scores
We’re fairly happy with that list of domains, but let’s make one last quick check — do any of them have a high Domain Risk Score per DomainTools Iris? Afterall, domains and risk scores go together like cake and frosting. We’ll check the scores by running 2,477 queries using the official DomainTools command line client.
domaintools iris_investigate --domain "10doigtset1cupcake.fr" | jq -r \ '"\(.response.results[].domain_risk.risk_score) \(.response.results[].domain)"'; sleep 3
domaintools iris_investigate --domain "123cupcake.com" | jq -r \ '"\(.response.results[].domain_risk.risk_score) \(.response.results[].domain)"'; sleep 3
domaintools iris_investigate --domain "123cupcake.nl" | jq -r \ '"\(.response.results[].domain_risk.risk_score) \(.response.results[].domain)"'; sleep 3We’ll assume that you’ve edited your original results file as shown above. We’ll run the commands from that file and redirect the output to a “risk-results.txt” file. Our embedded “sleep” commands means that this job will run for a couple of hours while we work on other things. The pause between commands are meant to ensure our script doesn’t exceed our target rate limit of no more than 20 queries/minute.
$ sh -x cupcake-e2ld-trimmed.txt > risk-results.txtThe results in risk-results.txt should look like:
4 10doigtset1cupcake.fr
24 123cupcake.com
3 123cupcake.nl
[...]If, instead, you see “results” that look like:
(.response.results[].domain_risk.risk_score) (.response.results[].domain)
(.response.results[].domain_risk.risk_score) (.response.results[].domain)
(.response.results[].domain_risk.risk_score) (.response.results[].domain)
[...]That means you’ve forgotten the critical backslashes before the opening parentheses in your commands, and your JSON references are being treated as if they were string literals instead of actual JSON values to be displayed.
We’ll forgo showing you the results of all 2,477 of those runs, but we can sort the values by saying:
$ sort -nr risk-results.txt > risk-results-sorted.txtLet’s take a look at a few of the values, defanged for display:
$ cat risk-results-sorted.txt
100 tumediocupcake[dot]com
100 thecupcake[dot]de
100 sweetscupcake[dot]com
99 countrysideenormouscupcake[dot]com
98 doomcupcake[dot]com
97 embarrassmentcupcake[dot]com
97 cupcake[dot]space
94 slumcupcake[dot]space
94 cloud-cupcake[dot]com
94 cartooncupcake[dot]com
93 daddyandcupcake[dot]online
91 doityourselfcupcake[dot]com
90 compostcupcake[dot]com
90 cloud9cupcake[dot]com
[* * *]
1 coffeeandcupcake[dot]se
1 cocoscupcake[dot]com
1 cococupcake[dot]pl
1 cococupcake[dot]com
1 charmingcupcake[dot]com
1 centralcupcake[dot]com
1 candycupcake[dot]de
1 cafecupcake[dot]se
1 cafecupcake[dot]dk
1 buildacupcake[dot]com
1 buildacupcake[dot]co.uk
1 boutiquecupcake[dot]co.uk
1 beyondcupcake[dot]com
1 bemycupcake[dot]se
1 awesomecupcake[dot]com
1 atomiccupcake[dot]ca
1 amycupcake[dot]de
1 allthingscupcake[dot]com
1 acupcake[dot]co.uk
0 vannesscupcake[dot]nl
0 topazcupcake[dot]com
0 thegoodadvicecupcake[dot]com
0 theboutiquecupcake[dot]uk
0 theboutique-cupcake[dot]uk
0 studiocupcake[dot]nl
0 storminacupcake[dot]co.uk
0 smashingcupcake[dot]de
0 shopthegoodadvicecupcake[dot]com
0 pushpopcupcake[dot]com
0 pinkcupcake[dot]de
0 photoonacupcake[dot]co.uk
0 olacupcake[dot]uk
0 mycupcake[dot]ch
0 mscupcake[dot]uk
0 mrcupcake[dot]de
0 mecupcake[dot]my
0 makeabirthdaycupcake[dot]com
0 lovecupcake[dot]nl
0 letscupcake[dot]no
0 himycupcake[dot]co.uk
0 heavencupcake[dot]nl
0 godivacupcake[dot]com
0 deincupcake[dot]de
0 customcupcake[dot]co.uk
0 cupcake[dot]eu
0 cupcake[dot]ch
0 corporatecupcake[dot]co.uk
0 chocolatecupcake[dot]my
0 carmenscupcake[dot]ch
0 cappucupcake[dot]com.ph
0 callmecupcake[dot]se
0 boutiquecupcake[dot]uk
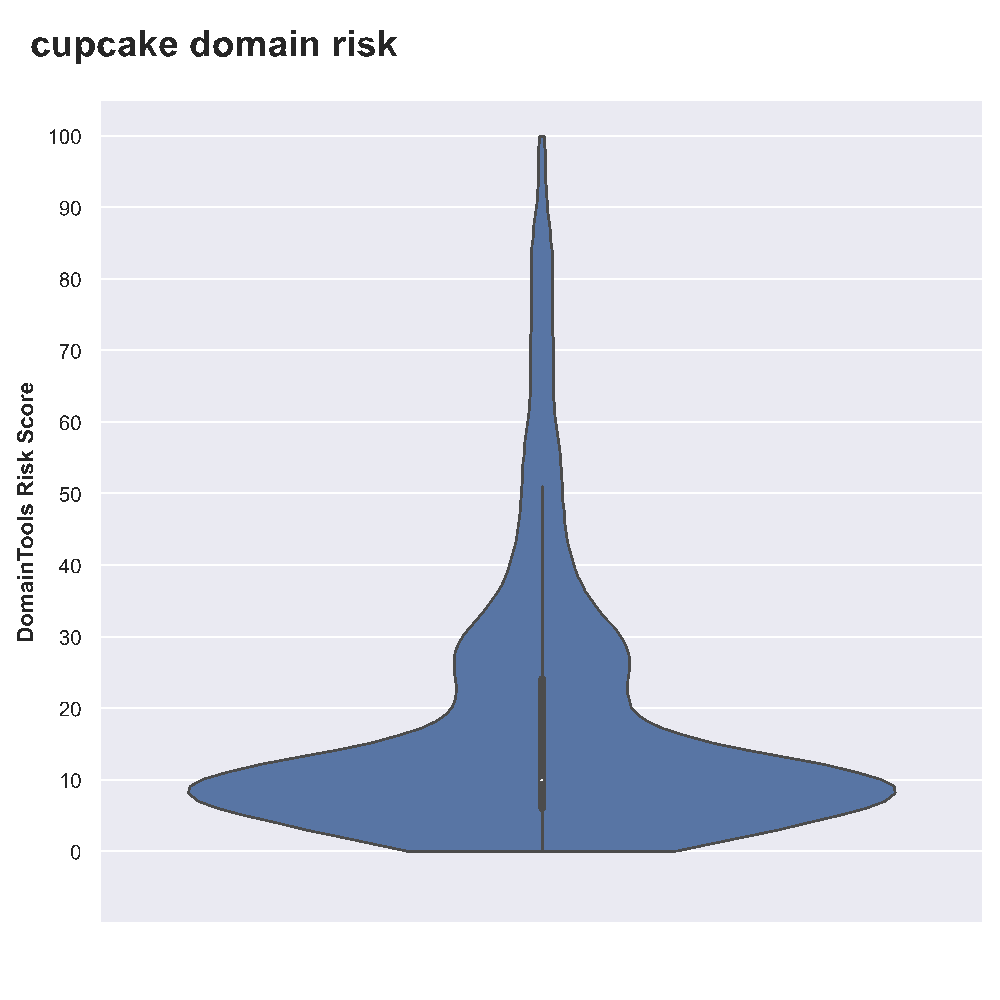
0 bloomincupcake[[dot]comIt’s hard to visualize risk scores without a risk distribution graph. To generate the following violin plot, we’ll assume you’ve modified the above risk results file to have a comma between the two columns of values, and have added risk,domain as a header row in the file. Code to produce this graph is in Appendix B, adapted from “Domains That Begin With A Digit: Risk Profiles for Selected ASNs.”
Obviously most–but not all–of our cupcake domains are comparatively low-risk. Thus, returning to our fictitious example, we’d now have a good sense for which cupcake-related domains currently exist and what limits we have for finding a name, and we’d also have a sense for the overall riskiness of these domains. This is good data for us as we plan our tasty business empire!
Conclusion
Because Farsight DNSDB is a massive database of passive DNS information, it also is a wealth of information about currently active domain names. Using DNSDB Flexible Search, you can find domains matching specific keywords and pull a subset of them down for further analysis, such as, for example, enriching those domains with the DomainTools Domain Risk Score. This solution provides you the power to explore the set of domains and subdomains at the scale you need to help discover, track, or take action on domains relevant to you or your organization.
DNSDB cannot, unfortunately, help you purchase cupcakes. We recommend your locally-owned bakery instead.
Appendix A: 2nd-level-dom-large
#!/usr/bin/perl
use strict;
use warnings;
use IO::Socket::SSL::PublicSuffix;
my $pslfile = '/usr/local/share/public_suffix_list.dat';
my $ps = IO::Socket::SSL::PublicSuffix->from_file($pslfile);
while (my $line = <STDIN>) {
chomp($line);
my $root_domain = $ps->public_suffix($line,1);
printf( "%s\n", $root_domain );
}Appendix B: make-cupcake-violin.py
#!/usr/local/bin/python3
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
### variables we're reading in: score,domain
### assume those column names are present in the CSV format data file
datafile='risk-results-sorted.txt'
df = pd.read_csv(datafile)
plt.figure(figsize=(6, 6))
### use the default seaborn theme (gray background, white grid lines)
### https://seaborn.pydata.org/generated/seaborn.set_theme.html
sns.set_theme()
### I quote: 'Many people find the moderated hues of the default
### "deep" palette to be aesthetically pleasing', other options at
### https://seaborn.pydata.org/tutorial/color_palettes.html
sns.color_palette("deep")
### set_context tweaks a bunch of font parameters
sns.set_context("paper")
### https://seaborn.pydata.org/generated/seaborn.violinplot.html
### cut = 0 ensures the violins won't extend beyond the observed data
### scale options? None of the options are perfect/all have limitations.
ax = sns.violinplot(data=df, y='risk', cut=0, scale='count')
first_title="cupcake domain risk\n"
mytitle=first_title
plt.suptitle(mytitle, size=16, fontweight="bold", y=.97, x=.03,
horizontalalignment='left', verticalalignment='top')
plt.autoscale(enable=False, axis='both', tight=True)
### handle the horizontal axis (no axis label required)
plt.xlabel('')
plt.xticks(fontsize=10, weight='bold')
### handle the vertical axis
### the y is set to 104 to ensure we get the 100 label intact
plt.ylabel('DomainTools Risk Score', fontweight="bold")
plt.yticks(np.arange(-10, 104, step=10))
### maximize usable space by asking for tight margins
plt.subplots_adjust(left=0.1, right=0.98, top=0.90, bottom=0.08)
### This final obscure code lays a white blob over the bottom-most Y axis label
### because I don't want it to say "-10" on the graph (yes, this is a hack)
ax.annotate(' ', size=10,
xy=(0,-7), xycoords='data',
xytext=(25,-15), textcoords=('figure points','offset points'),
bbox=dict(boxstyle='round',pad=.6,facecolor='white',edgecolor='white'))
plt.draw()
myplot='bar-plot.pdf'
plt.savefig(myplot,dpi=300)


