

Introduction
DNS TXT records are the “kitchen junk drawer” of DNS. They are often used to store miscellaneous data that isn’t a good fit for any of the other more narrowly-defined DNS record types, such as A, AAAA, CNAME, MX, NS, or other record types.
There’s a lot that you can potentially uncover in TXT records, but until recently, they were hard to search simply because they weren’t rigidly structured the way most other DNS RRtypes are. In this post, we will review two specific uses of TXT records, “control strings” and SPF entries, and review how to search for them in DNSDB using Flexible Search, highlighting it in Scout, our APIs, and in our command line tools.
“Control Strings” in DNS TXT Records
Software and online service vendors often want to confirm that they’re dealing with a person who is in operational control of a domain. Demonstrating operational control can be accomplished via a number of different mechanisms, but as a practical matter, is often accomplished via DNS.
The way this works is simple: the vendor asks the customer to create a DNS TXT record under that domain with unique content specified by the vendor. Such requests are known as “control strings.” If the person can successfully create the requested TXT record with the control string, most vendors are confident they are dealing with the person in charge of that domain.
The use of control strings have an unintended side effect: it can allow the entire world to view the products or services a site may be using. This may have several implications. How you view those implications may vary, depending on your role:
- Vendors Requiring Use of the Control String Approach: Hypothetically, a vendor might believe “If we require you to create a record with a control string, it’s because we need the role-assurance that control strings can demonstrate. This mechanism is free, easy, and it just works. What’s not to like?”
- The Customer Publishing the Control String: If a customer wants to use a specific product or service, they may have no choice but to comply with the vendor’s demand – or pick another product.
- Vendor’s Competitors: In a competitive marketplace, being able to identify parties using a given product can be very useful for a competitor’s salespeople – “Oh! Site X uses [competitor’s product]. We should see if X would be interested in switching to us instead.”
- Attackers Interested in a Particular Site: Attackers often conduct pre-attack reconnaissance of their selected target site. If the attacker checks their target’s TXT records, they may discover parts of a target site’s software environment. That may help the attacker select or tune appropriate exploits.
- Attackers Interested in Any Site Using a Specific Product: In the preceding bullet, we assumed an attacker settled on the site they wanted to attack. Often, however, the attacker may be combing for sites running a particular product. I’m sure attackers are happy to discover that by checking TXT records they can easily build a list of all customers using specific products, eh?
We will show examples of control strings below in the section, “What Do We See in a Typical TXT Record?”.
SPF Entries in DNS TXT Records
Sender Policy Framework records (SPF) are used to define the IP addresses permitted to emit email for a given domain name (see https://en.wikipedia.org/wiki/Sender_Policy_Framework), and, by extension, define that all the other IPs should not. SPF isn’t a perfect solution, so many sites combine SPF with two additional validation solutions: DKIM (see https://en.wikipedia.org/wiki/DomainKeys_Identified_Mail) and DMARC (see https://en.wikipedia.org/wiki/DMARC). We will focus solely on SPF entries.
SPF records are published in DNS TXT records. While there was a SPF-specific DNS resource record type, it was deprecated in favor of using TXT records. SPF records typically include:
- The IP addresses of an entity’s own mail servers;
- Lists of third-party mail senders that are used by the site, typically in the form of “include” entries; and
- A final “catch-all” pattern that explains how email from anywhere else should be handled.
This information is needed for SPF to be able to do its job. However, publication of an SPF record tends to “shine a spotlight” on the resources it catalogs, just as robot.txt files (see https://en.wikipedia.org/wiki/Robots.txt) often serve to highlight precisely the content that a site least wants to have crawled by web search engines.
Information leakage from SPF records isn’t catastrophic, but it does potentially increase a site’s attack surface, and is an exposure that should be managed when possible. We’ll look at examples of SPF data below.
What Do We See in a Typical TXT Record?
We’ll use the theme of electric car makers in this example, beginning with Elon Musk’s electric vehicle company, Tesla.
Tesla
Let’s take a look at the complete set of DNS TXT records for tesla.com. Multiple records get returned, including both control strings (italicized) and SPF records (bolded):
$ dig tesla.com txt +short | sort "55zNJIDU0xk94IfGJtL+Hh+wje5JzOS6GY+ntggZF908AUsx0LBKgr+Nln3CgZEUifxSuN09M05jYpdbd6+cpw==" "MS=ms22358213" "SFMC-qkAv7SvlQaslp7NEALX8t68s_AZWOQB6ThKQS5l5" "T0E0S29854" "adobe-idp-site-verification=321c026a-3a8c-4206-a1fa-391a59585c54" "adobe-sign-verification=efb2da198047b7a154bd604d2721038b" "apple-domain-verification=C9J7eOtEbm7Dqr88" "bugcrowd-verification=40bd5dd89a6e4073ca9bc76feac3a47b" "docker-verification=74d1ec4e-a7a6-48a7-9568-9bd0faac833f" "google-site-verification=Y7lbse5bSatjXaqSBOWXjsit4mOp9cQzfLDpnQUSZlg" "logmein-domain-confirmation=9zxwVn2buGWrLtU24J88" "ms-domain-verification=e335cec9-0ff5-4a54-b8bc-8966a8d146db" "teamviewer-sso-verification=2fc989f75b19494fab5eb0e2c22dd625" "traction-guest=b4f7ad59-bf17-4b3c-8b36-9c2d28f1de32" "v=spf1 ip4:54.240.84.225/32 ip4:54.240.84.226/31 ip4:54.240.84.228/30 ip4:54.240.84.232/29 ip4:54.240.84.240/29 ip4:54.240.84.248/30 ip4:54.240.84.252/32 ip4:44.239.249.139 ip4:52.24.70.112 ip4:34.223.204.78 ip4:213.244.145.203 ip4:213.244.145.219 ip4:213" ".244.145.204 ip4:213.244.145.220 ip4:8.47.24.203 ip4:8.47.24.219 ip4:8.47.24.204 ip4:8.47.24.220 ip4:8.45.124.203 ip4:8.45.124.219 ip4:8.45.124.204 ip4:8.45.124.220 ip4:8.21.14.203 ip4:8.21.14.219 ip4:8.21.14.204 ip4:8.21.14.220 ip4:8.21.14.194 ip4:8.21.1" "4.211 ip4:212.49.145.0/24 ip4:91.103.52.0/22 ip4:168.245.123.10 ip4:216.81.144.165 ip4:149.72.247.52 ip4:149.72.134.64 ip4:149.72.152.236 ip4:149.72.163.58 ip4:149.72.172.170 ip4:167.89.90.62 ip4:158.228.129.79 ip4:216.81.144.165 ip4:117.50.14.178 ip4:117" ".50.35.199 include:u13494342.wl093.sendgrid.net include:spf.protection.outlook.com include:mail.zendesk.com include:_spfsn.teslamotors.com include:_spf.qualtrics.com include:_spf.ultipro.com include:_spf.psm.knowbe4.com -all" "zapier-domain-verification-challenge=64e810e8-0fe1-4de0-b104-229592811c5b"
In terms of control strings, we see entries from Adobe, Apple, Docker, Google, LogMeIn, Microsoft, TeamViewer, and others. Other entries in that TXT record include “bare hashes” with no indication of what they’re about — those do a nice job of minimizing information leakage while still (presumably) accomplishing their likely-intended role as a control string.
In terms of SPF, let’s look at the three highlighted bits:
v=spf1— this declares that this is a version 1 SPF record. You may sometimes also see version 2 records, sometimes referred to as “sender ID” records — see https://en.wikipedia.org/wiki/Sender_Policy_Framework and https://en.wikipedia.org/wiki/Sender_ID for more on the differences between the two."include:spf.protection.outlook.com"means that outbound email from this domain may be coming from Microsoft Exchange Online (see https://learn.microsoft.com/en-us/microsoft-365/security/office-365-security/email-authentication-spf-configure?view=o365-worldwide), and- The record has a “hard fail” catch-all (
"-all") acting as a default rule at the end of its SPF entry.
Given that it has been reported that “91% of all cyber attacks begin with a phishing email to an unexpected victim,” (see for example https://www2.deloitte.com/my/en/pages/risk/articles/91-percent-of-all-cyber-attacks-begin-with-a-phishing-email-to-an-unexpected-victim.html ), knowing that a site’s using Microsoft Exchange Online may give an attacker a “leg up” if they were targeting Tesla.
Rivian
Rivian, another electric car manufacturer here in the United States, apparently also uses Microsoft Exchange Online. Let’s check out the complete set of TXT records for rivian.com:
$ dig rivian.com txt +short | sort "3i1npesq9hqoq48bhklpnlkogq" "Dynatrace-site-verification=40027b27-2255-4575-9969-d9d86cfd017a__61tpnk6bt6n3dmohag876je96c" "MS=ms71873047" "adobe-idp-site-verification=381f0106b42293d4d8223bab3d695ef768e95efed25777f8c1052696e84afefc" "amazonses:pAvIM4KFMb3PVNmIEGF4mBenrIs1O3BYlZH+bWc7LI8=" "apple-domain-verification=xfkVPKVmmID4BTRj" "atlassian-domain-verification=FwmD6Qw7VSdYoMJ+Ar3o6uZsIv1Bx+TI68SXmWlooItlnkDhQcNv6MClkhHXgbjg" "atlassian-domain-verification=X3FdlpwOyA6/NENGVmTAwRiTwav1sasIX2Z1eiq8/lo/ncvdpbtA1ZbzQPkr4CMa" "atlassian-domain-verification=Yj5MeUSO99HZpvppeIepXuKpKKrwe8KVuDKIvYVtt3O/Fe/yfqRYhoAdAUre2cDS" "atlassian-domain-verification=Zqd0ap54AB0TGjdDNg4smc0LOZsn5Xxzk44g6uV9UYvhIBDa9prQ3gxCdjoZqYAO" "atlassian-domain-verification=pa0mqCBOV0raECEyH/PAy2IaSlUmX0zq84wjjfx48QOfhg/t9r1Hzbfn8sZ3Bz0M" "docusign=7ed79ca7-f292-4f21-bf4c-acb00640910b" "g240t24f56sjquket4hg9rbbq3" "google-site-verification=-p7AWPFGZJbjCeRT5KepyrSfNzZg7qdEDMqrFpv-6RQ" "google-site-verification=L0ux3YgiB_7XdWr2aqNK6sHwQXN1I6zv2oswE2CCYw4" "google-site-verification=OQOixmx_VosSpkq-hqHLCQW903s_lWb14bqaBTmgXCE" "google-site-verification=hZtOSI76uEw2Y8CWb3a46YvBY_E7FKlMhDqfGICkkLU" "google-site-verification=kCll6LrGMLURYde2FfQIKPvrmJ5gvqXLrHQXlJzj5u8" "h1-domain-verification=UUhCio7nfm2NaYq3nQRhXNuY5SQQU8Yq2CmzPaFAE79VfaxG" "qq81fq4famp4eathsspb6ee18" "smartsheet-site-validation=63FFfNcNdZt3KOu6A3PFal2lZ5SHYdZp" "stripe-verification=ad2b4003089d30226167d8b643673f1835d15f5c37a2e426e1597acb3d173ed7" "traction-guest=c96b22f0-a31f-4606-9bb8-b81ce07e841a" "v=spf1 include:spf.protection.outlook.com include:spf-005c6a01.pphosted.com include:shops.shopify.com include:servers.mcsv.net include:amazonses.com ip4:3.13.43.126 ip4:23.249.216.183 ip4:23.249.216.184 ip4:54.87.171.97 -all"
We’ll note that Rivan has control strings for the Atlassian toolchain, DocuSign, SmartSheet, and Stripe, among some of the others we mentioned earlier. For SPF, we see several additional “include” entries, such as for Shopify, as well as the expected IP addresses and a “-all” entry.
Lucid Motors
Moving on, how about the luxury electric car company, Lucid Motors, at lucidmotors.com:
$ dig lucidmotors.com txt +short | sort
"Dynatrace-site-verification=82b092ea-bb07-451a-8c2f-bf60d2897caa__d5c3mnet6oih55hr640a8pbbv5"
"MS=37C18C7BE8A3D74885B94F317F3F06C4E08042A3"
"Zo6vZE30roynyg0QPI4sX3XLfPgdIsg"
"adobe-idp-site-verification=cebe0f6a7ee3ae9c1f6a0a626e7ea47f297303015cea6b29082250464589dbb8"
"amazonses:dxTlF27hLTqIBQE7uHKaE2IdiXdLRE0HzffNCmOebL0="
"amazonses:e1g03jc9AYflQkXCrHMCUv4v2y7mMBWpyBE8uqZ2Kn4="
"apple-domain-verification=iY5vLy8h4mqkOoKe"
"atlassian-domain-verification=ufAnCykTV/t4bcwDFMXziK5mUnJmPlz1+AzPyyAYnJrDB1AbIbz7uJsJca8mc0Qo"
"citrix-verification-code=09bc4650-be1e-44f8-8a53-b75bf4386e7d"
"docusign=06553209-1218-48ca-855e-74fb30742a88"
"facebook-domain-verification=lw17ysflht1dfjhino2tlngnvq5wly"
"google-site-verification=f9olDtTF9wuadtweCwjhLg9C516rVZVFfbS9JDd20Ps"
"mongodb-site-verification=SIMh2KA0ZPWeAnMCToNx8IfVt5FQjTiT"
"onetrust-domain-verification=5fe9809a61204a98b685215fb9df866c"
"onetrust-domain-verification=d7d9a7c88a624dc7b2cf624364bb625e"
"stripe-verification=8f9a01f0407ff5c3e43cbb64e6beb1953d5511e247a0751e5116ed597eca8b65"
"stripe-verification=ae2201a1e60351074c7085133d80d9495cc85899ae3fc15838671299584f88f5"
"stripe-verification=bed3e7f84db3cf56ad5f70f68e874b886affc7d3160d5a42aaf10558c46e6e68"
"v=spf1 include:us._netblocks.mimecast.com include:spf.protection.outlook.com include:servers.mcsv.net include:_spf.salesforce.com exists:%{i}._spf.lucidmotors.com include:mailgun.org -all"
Yep, looks like Lucid Motors is using Microsoft Exchange Online, too. They also allow Salesforce to send emails on their behalf. Lucid Motors also has several other interesting control strings, including Facebook, MongoDB, and OneTrust.
Searching TXT Records in DNSDB
Visual inspection of control strings and SPF records highlight patterns which we can search for inside of DNSDB. For example, to find other sites that have SPF records indicating usage of Microsoft Exchange Online, we can write a FCRE (“Farsight Compatible Regular Expression”) see https://www.domaintools.com/resources/user-guides/dnsdb-farsight-compatible-regular-expressions-fcre-reference-guide/):
^"v=spf1.*include:spf\.protection\.outlook\.com.*-all"$
“Decoding” that FCRE:
^ | “Beginning at the start of this field” (^ means “left anchor this pattern”) |
"v=spf1 | Find a literal double quote mark, the letter v, an equal sign, then SPF1 |
.* | Allow any zero or more characters here |
include:spf\.protection\.outlook\.com | Then find exactly this literal pattern of characters (note: \. = literal dot) |
.* | Allow any zero or more characters here |
-all" | Find a literal dash, the leters “all”, and a closing double quote |
$ | Then immediately end the pattern ($ = “right anchor”) |
We’ll find patterns in TXT records that match that specification using DNSDB Flexible Search. Flexible Search is a terrific “finding aid” that helps you find hits in DNSDB that you couldn’t find using just the queries available in DNSDB Standard Search. Access to Flexible Search comes bundled with DNSDB API subscriptions at no additional charge.
Flexible Search can be used from:
- DNSDB Scout, the graphical web client,
- The dnsdbflex command line tool, and
- The DNSDB API RESTful interface
We’ll illustrate all three approaches below.
Flexible Search in DNSDB Scout
We’ll search for our regular expression (our “pattern of interest”) using DNSDB Flexible Search via DNSDB Scout (see https://www.farsightsecurity.com/tools/dnsdb-scout/).

Upon clicking the search button in Figure 1, results are found and reported in Figure 2. Looking at those, we see that we’ve found a lot of patterns that include our string of interest — over 69,000 different variations combining our primary strings of interest plus other miscellaneous SPF “bits and bobs.”
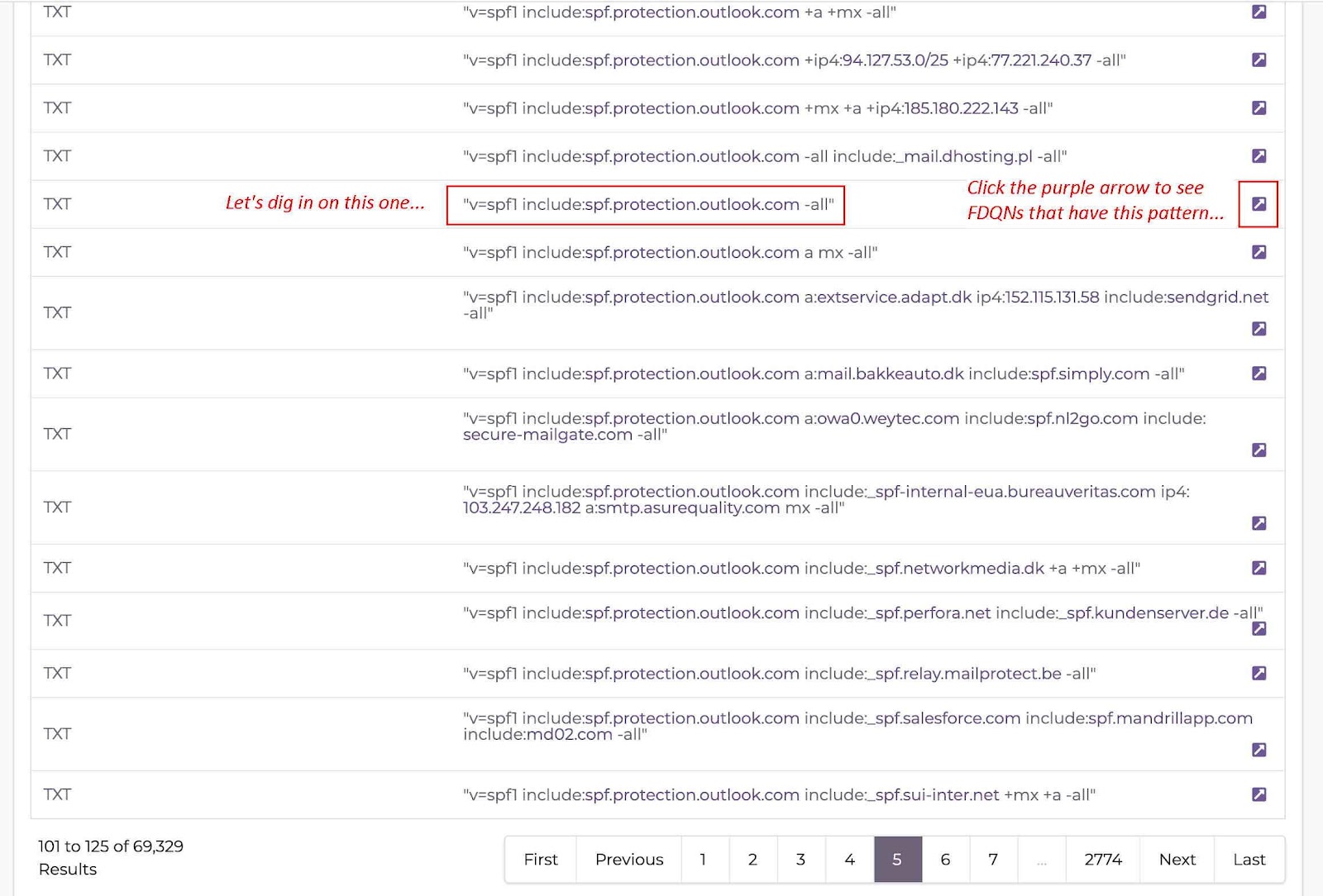
Note that we don’t see any domain names listed “on the left” where we normally see RRnames shown in a DNSDB Standard Search. That’s because our Flexible Search Rdata search results expose the exact patterns seen in the right hand side of TXT records in the DNS database, not which domains may use each of those exact patterns.
Now that we have a list of over 69,000 results, we can begin to explore those. But how? The answer is “click the purple arrow” over at the right hand margin of each line of Flexible Search results. This allows us to look at the set of domains using this exact pattern. Doing that sets up a new DNSDB Standard search for domains that have the exact pattern of the specific row we selected.
As shown in Figure 3, the raw hex-encoded string associated with the exact pattern you selected gets automatically populated into the new DNSDB Standard Search query when you click the purple arrow.

Scrolling down after searching, we can see our 26 hits for this particular pattern. Remember, those 26 represent matches for just one out of all 98,096 total exact patterns found in Flexible Search, and just for a brief half day period. Looking at just this set of 26 hits and sorting by count, the busiest (highest count) hits for this particular pattern are listed in Figure 4.

What about all the other unique exact patterns Flexible Search uncovered for us? Answer: they still remain to be explored.
Anyone looking at the above process in the context of 69,000+ hits will probably think “Gosh — over 69,000 unique patterns, each of which may in turn be associated with lots of domain names. Exploring all those in Scout would involve a lot of clicking, particularly since there’s no indication of which patterns found in the initial Flexible Search have the highest subsequent Standard Search counts.” There are solutions here: automation implemented via commandline tools and APIs.
Searching with dnsdbflex and dnsdbq
Our initial Flexible Search for SPF records related to Microsoft Exchange Online using Scout yielded over 69,000 unique patterns. How can we find all of the matching domains? Let’s try scripting this using our command line clients, dnsdbflex (https://github.com/farsightsec/dnsdbflex) and dnsdbq (https://github.com/dnsdb/dnsdbq). This process involves two phases: first doing a Flexible Search with dnsdbflex, and then using its output to do a Standard Search with dnsdbq.
In the first phase, the “Flexible Search” phase, we’ll use dnsdbflex to make a Flexible Search query that’s equivalent to the one we made in DNSDB Scout:
$ dnsdbflex --regex '^"v=spf1.*include:spf\.protection\.outlook\.com.*-all"$' -s rdata -t txt -A 24h -l 0 -F > myhits.txt
“Decoding” the parameters to that command:
--regex pattern | This means “make a regular expression search for the specified pattern.” |
-s rdata | We can search the left hand side (rrnames) or the right hand side (rdata); we choose rdata |
-t txt | This parameter lets us limit our search to just one RRtype, TXT records |
-A 24h | This asks for results ONLY from the last 24 hours (one day) |
-l 0 | Dash ell zero means “return up to the max number of results” (1 million) |
-F | This asks for results to be formatted suitably for injestion into dnsdbq -f (batch mode) |
> myhits.txt | Put the results from this run into the file “myhits.txt” |
Running that command resulted in 137,928 lines of output:
$ wc -l myhits.txt 137,928 myhits.txt ← commas added manually here and below for readability
If you’re reading carefully, you’ll notice that the number of results in our output file appears to be roughly twice as large as was reported in DNSDB Scout. Let’s look at what a few of those hits look like (long lines wrapped to fit this document’s format):
$ more myhits.txt rdata/raw/06763D737066310161026D781D613A686F73742E6C6561726E666F726365706172746E6572732E636F6D136D783A6D61696C2E6C616D626572732E636F6D116D783A6C616D626572736370652E636F6D106970343A35342E3232352E39382E3838116970343A36362E3133322E3133302E3438116970343A36362E3133322E3133302E3435126970343A36362E3133322E3133322E31313922696E636C7564653A7370662E70726F74656374696F6E2E6F75746C6F6F6B2E636F6D26696E636C7564653A353036323338382E73706630322E68756273706F74656D61696C2E6E6574042D616C6C/TXT # rdata/name/"v=spf1" "a" "mx" "a:host.learnforcepartners.com" "mx:mail.lambers.com" "mx:lamberscpe.com" "ip4:54.225.98.88" "ip4:66.132.130.48" "ip4:66.132.130.45" "ip4:66.132.132.119" "include:spf.protection.outlook.com" "include:5062388.spf02.hubspotemail.net" "-all"/TXT rdata/raw/06763D737066310161026D7822696E636C7564653A7370662E70726F74656374696F6E2E6F75746C6F6F6B2E636F6D1C696E636C7564653A7368617265706F696E746F6E6C696E652E636F6D042D616C6C/TXT # rdata/name/"v=spf1" "a" "mx" "include:spf.protection.outlook.com" "include:sharepointonline.com" "-all"/TXT rdata/raw/06763D73706631026D7822696E636C7564653A7370662E70726F74656374696F6E2E6F75746C6F6F6B2E636F6D16696E636C7564653A5F7370662E616E70646D2E636F6D13613A6D61696C312E736D74706D61696C2E7365042D616C6C/TXT # rdata/name/"v=spf1" "mx" "include:spf.protection.outlook.com" "include:_spf.anpdm.com" "a:mail1.smtpmail.se" "-all"/TXT [etc]
Each line of results in that file is either:
- A raw hex string search string, or
- A human-readable comment, prefixed with a pound sign.
The comment “decodes” or “explains” the raw hex query string found on the preceding line. The presence of that comment allows you to use a text editor to scan through the file of results, deciding which (if any) of those results you’d like to process further.
For this example, let’s assume that in this case we’re interested in all the results we found, so we’ll retain all of the hits found by dnsdbflex.
We’re now ready to start the second part, the “Standard Search” phase. We’ll pipe the results we found as output from dnsdbflex as input into dnsdbq:
$ dnsdbq -ffm -A 24h -l 0 -T datefix -j < myhits.txt > matches.jsonlDecoding the parameters to that command:
-ffm | Enable parallel batch lookup mode. Up to 10 queries will run at the same time. Each “chunk” of results will start with a “++” line showing the query associated with the chunk, and each “chunk” of results will be closed out with a “ --” line reporting the status of the run at its conclusion. These need to be filtered out before the results constitute valid JSON Lines output. |
-A 24h | This asks for results from the last 24 hours |
-l 0 | Dash ell zero means “return up to the max number of results” (1 million) |
-T datefix | This tells dnsdbq to return “human format” date times rather than raw Un*x seconds |
-j | Output in JSON Lines format (“++” and “--” seperators may need to be filtered) |
< myhits.txt | Read the input for this command from the file “myhits.txt” |
>matches.jsonl | Put the output from the command into the file “matches.jsonl” |
We received 315,690 lines of output when we ran the above command:
$ wc -l matches.jsonl
315,690 matches.jsonl
Of those 315,690 lines, 177,762 lines consisted of either “++” lines or “--” lines:
$ cat matches.jsonl | egrep -v "^(\+\+|\-\-)" | wc -l 177,762
Recall that the “++” lines show the exact raw hex query that was made, and the results that follow. For example:
$ head -2 matches.jsonl
++ rdata/raw/06763D737066310161026D781D613A686F73742E6C6561726E666F726365706172746E6572732E636F6D13
6D783A6D61696C2E6C616D626572732E636F6D116D783A6C616D626572736370652E636F6D106970343A35342E3232352E39382E3838116970343A36362E3133322E3133302E3438116970343A36362E3133322E3133302E3435126970343A36362E3133322E3133322E31313922696E636C7564653A7370662E70726F74656374696F6E2E6F75746C6F6F6B2E636F6D26696E636C7564653A353036323338382E73706630322E68756273706F74656D61696C2E6E6574042D616C6C/TXT
{"count":277,"time_first":"2019-02-19 15:01:22","time_last":"2023-01-17 18:29:56","rrname":"lambers.com.","rrtype":"TXT","rdata":["\"v=spf1\" \"a\" \"mx\" \"a:host.learnforcepartners.com\" \"mx:mail.lambers.com\" \"mx:lamberscpe.com\" \"ip4:54.225.98.88\" \"ip4:66.132.130.48\" \"ip4:66.132.130.45\" \"ip4:66.132.132.119\" \"include:spf.protection.outlook.com\" \"include:5062388.spf02.hubspotemail.net\" \"-all\""]}
Each of the “++” entries will obviously be unique.
On the other hand, the “--” lines report just the summary status code for the preceding block of results. For those, we see only two different results:
$ egrep "^-- " matches.jsonl | sort | uniq -c
68906 -- NOERROR (no error)
58 -- NOERROR (no results found for query.)
You might be puzzled by the 58 “no results found for query” status lines. After all, we just ran Flexible Search to find these patterns. Why would there be no results in Standard Search for a Flexible Search query pattern we just found?
We first found all the exact matching patterns in Flexible Search for a twenty-four hour relative time fence. Some of those results might only be rarely seen. After the entire Flexible Search phase finished, we then ran the Standard Search phase. The Standard Searches also used a twenty-four hour time fence just like the Flexible Search phase, but that subsequent relative time fence doesn’t exactly align with the previous relative time fence — it started later, and ended later.
In some cases, rarely-seen hits that happened to be seen near the beginning of the Flexible Search’s relative time interval might not actually be seen during the slightly later (and non-perfectly-overlapping) Standard Search time interval. If this discrepancy bothers you, one easy solution is to use absolute rather than relative values for time fencing, thereby ensuring that Flexible Search and Standard Searches are looking at the exact same time window.
To produce a valid JSON Lines file of results:
- Remove the “++” and “
--” lines - Extract the Rrnames with
jq (https://stedolan.github.io/jq/) - Sort and uniquify the Rrnames, and
Save what’s left to the file “matching-rrnames.txt“
$ cat matches.jsonl | egrep -v "^(\+\+|\-\-)" | jq -r '.rrname' | sort -u > matching-rrnames.txt
That command pipeline leaves us with 177,384 unique FQDNs that have the originally-specified matching string in a TXT record:
$ wc -l matching-rrnames.txt
177,384 matching-rrnames.txt
We may only be interested in the “base” (“registrable”, or “effective 2nd-level”) domains associated with the various FQDNs. If that’s the case, we can run the FQDNs through a little script (2nd-level-dom-large, see Appendix I) and then sort and uniquify the results:
$ 2nd-level-dom-large < matching-rrnames.txt | sort -u > matching-basenames.txt
$ wc -l matching-basenames.txt
135,214 matching-basenames.txt
We then have a list of base domain names associated with the specified pattern (defanged for display here):
$ more matching-basenames.txt
001-traductions[dot]fr
0049[dot]productions
0073[dot]co.jp
[…]
Zzrjllp[dot]com
Zzrobotics[dot]at
The above may seem like it’s all somewhat tedious, but it actually runs faster than you might think. Before Flexible Search, we couldn’t have found these matches at all.
Using the DNSDB API To Search TXT Records (For Developers!)
We have a third option to search TXT records for content of interest: we can write our own code to directly query the DNSDB API. Here we will use Python 3 in our continuing example of searching for sites using Microsoft Exchange Online by inspecting SPF entries in their TXT records.
We will follow the same logic from the previous command line example. First we will read in one or more patterns from STDIN and do a DNSDB Flexible Search for exact patterns in Rdata that include the patterns of interest.
We’ll then do subsequent DNSDB Standard Search Rdata queries using each of the exact patterns we received as results from Flexible Search. There may be one — or millions(!) — of domain matches for each pattern we found from Flexible Search.
The core of that process is summarized in the following couple stanzas of near-pseudo code (in fact, this is actually valid Python3 code):
my_results = []
for line in stdin:
# find matching raw Rdata in Flexible Search
raw_right_hand_side_data = flex_search_rdata(line.rstrip())
my_results.append(raw_right_hand_side_data)
with mp.Pool(8) as p:
p.map(make_raw_rdata_query, my_results, chunksize=10)
p.close()
p.join()The rest is just a matter of writing the two query functions (flex_search_rdata() and make_raw_rdata_query()) and providing some support/formatting routines.
Let’s do flex_search_rdata() first. This function takes one argument as input, the pattern we want to search for. It will return a list of zero or more discovered results. The crucial central activity of the function is to build an appropriately formatted DNSDB Flexible Search API call, and then make that call to DNSDB using the Python3 requests library (see https://requests.readthedocs.io/en/latest/).
We can find the format for the DNSDB API call we need by checking the “DNSDB Flexible Search API Programmers Guide” at https://www.domaintools.com/resources/user-guides/dnsdb-flexible-search-api-programmers-guide/
In our case, because we want to find only TXT records, and we want to return up to a million results, and we’re only interested in results from the last day (24 hours*60 minutes*60 seconds=86400 seconds), that implies a flexible search URL that looks like:
flex_url = "https://api.dnsdb.info/dnsdb/v2/regex/rdata/" \
+ pattern + "/TXT?limit=1000000&time_after=-86400"Because access to DNSDB is limited to subscribers only, we also need to pass in our API key for authentication, and confirm the sort of output we want (JSONL Lines, the only option). We’ll do that via additional headers we’ll add to our query. (For now, let’s just assume that we’ve got the API key value already available in the variable my_apikey)
myheaders = {'X-API-Key': my_apikey, 'Accept': 'application/jsonl'}We’re then ready to make our call to DNSDB Flexible Search using the requests library:
r = requests.get(flex_url, headers=myheaders, timeout=3600)After that query gets made, we need to process our results, assuming everything went successfully (e.g., that we get a status code of 200).
The first thing we need to do is handle our Streaming Application Format (“SAF”) records. SAF records were added to DNSDB API Version 2 to make it possible to learn if all results had been received, or if additional results might potentially remain. You can read all about SAF records in https://www.domaintools.com/resources/user-guides/farsight-streaming-api-framing-protocol-documentation/
In a more complete example, we might make up to three supplemental “offset” queries to ensure we’re retrieving all available results, up to a maximum of four million total results (the one initial query of up to a million results plus three additional “offset” queries, each of up to a million additional hits). For now, we’re just going to strip and discard all SAF records.
We’re then going to take a hit (one result) from our stripped results and extract just the raw rdata field. These are the raw hex strings that represent each exact pattern found by Flexible Search.
For each of those patterns we extract, we’ll add them to a list of results. Once we’ve extracted all of those, we’ll return the full list. If for some reason we don’t get a successful status code, we’ll write an error message to stderr instead. This may not be beautiful or elegant Python3 code, but hopefully it will give you a sense of what we’re trying to do.
flex_results = []
# Status Code 200 == Success
if r.status_code == 200:
stripped_results = remove_saf_entries(r.text)
for ahit in stripped_results:
myhit=json.loads(ahit)
if len(myhit) == 1:
rhs_raw_rdata = myhit['obj']['raw_rdata']
flex_results.append(rhs_raw_rdata)
return flex_results
else:
sys.stderr.write(pattern+" returned code="+r.status_code+"\n")Now that we have a list of raw hex strings to search for from Flexible Search, let’s process those with a series of Standard Searches, one for each of those raw hex rdata strings. We’ll write another little function to do that.
Again, we need to construct an appropriate URL. Checking https://www.domaintools.com/resources/user-guides/farsight-dnsdb-api-version-2-documentation/ we build a URL string that looks like:
url = "https://api.dnsdb.info/dnsdb/v2/lookup/rdata/raw/" + \
one_raw_hex + "/TXT?limit=1000000&time_after=-86400"
The above URL assumes we only want to search the right hand side of TXT records, we want up to a million results for each query, and we want results going back 86400 seconds (24 hours). Just like our first Flexible Search query, our Standard Search query for raw rdata will be made via the requests library with an appropriate header. Assuming that query goes well, we’ll extract the field or fields we want, and print them to stdout. In this case we’re only going to extract and print the Rrnames. Putting that all together:
for one_raw_hex in raw_rdata:
# we're hardcoding queries just for TXT records for this example
url = "https://api.dnsdb.info/dnsdb/v2/lookup/rdata/raw/" + \
one_raw_hex + "/TXT?limit=1000000&time_after=-86400"
myheaders = {'X-API-Key': my_apikey, 'Accept': 'application/jsonl'}
r = requests.get(url, headers=myheaders, timeout=3600)
# Status Code 200 == Success
if r.status_code == 200:
stripped_results = remove_saf_entries(r.text)
for myresults in stripped_results:
myresults_json_format = json.loads(myresults)
myrrname = myresults_json_format['obj']['rrname']
sys.stdout.write(myrrname+"\n")
sys.stdout.flush()
else:
sys.stderr.write(raw_rdata+" returned status code="+r.status_code+"\n")The rest of our program is a matter of utility/support routines and other “scaffolding” needed to support that primary code. The full program ("search_txt_records.py") is available for your review in Appendix II. Let’s now try our code on a few examples.
Example A: SPF Records for Microsoft Exchange Online
To run our little Python3 program, let’s assume we want to look for any TXT record from the past 24 hours that includes the regular expression string we used earlier for Microsoft Exchange Online:
^"v=spf1.*include:spf\.protection\.outlook\.com.*-all"$That string is characteristic of many sites that have outsourced their email to Microsoft, as we saw in our “electric vehicles” section, previously. We’ll put that line in the file “test_data.txt”, then make our Python3 code executable, and run it:
$ chmod a+rx search_txt_records.py
$ date ; ./search_txt_records.py < test_data.txt > test_data.output ; date
Tue Jan 17 22:48:19 PST 2023
Fri Jan 20 21:41:20 PST 2023
Subtracting those dates/times, that behemoth run took nearly three days to run (2 days, 22 hours, 53 minutes, 1 seconds (or 255,181 seconds)). Why did that take so long? Well, remember:
- We may be finding up to a million hits when making one Flexible Search and then…
- We’re going to be making up to a million additional DNSDB API Standard Searches
- This was run over a consumer broadband connection in the Pacific Northwest with relatively high latency to a DNSDB API server on the East Coast. Chatty protocols and large bandwidth delay products both slow us down.
Because of the number of potential searches, and because DNSDB API allows us to make up searches in parallel, we take advantage of Python’s Pool-based threading. That’s what gets handled (for the most part) by the little snippet of code mentioned near the start of this section:
with mp.Pool(8) as p:
p.map(make_raw_rdata_query, my_results, chunksize=10)
p.close()
p.join()We used 8 parallel threads for that run, but we could have asked for as many as 10. When we look at the output from our program, we see we got a medium large number of results: over 14 million of them.
$ wc -l test_data.output
14,357,865 test_data.output
Dividing the number of lines of output by the run time in seconds, we find that our code ran at 14,357,865/255,181=56.3 FQDNS per second on average. That’s far faster than clicking on hits in DNSDB Scout or piping results around in dnsdflex and dnsdbq.
How many unique effective 2nd-level domains do we see?
$ 2nd-level-dom-large < test_data.output | sort -u >
test_data_just-unique_2lds.txt
$ wc -l test_data_just-unique_2lds.txt
2,782,944 test_data_just-unique_2lds.txt
So, we discovered 2,782,944 base domains. Running over 255,181 seconds means we found 10.9 base domains/second on average.
Example (B): SPF Records for Google Workspace
For a second example, let’s search for an entry we might expect to see from sites that have outsourced their email to Google Workspace:
^"v=spf1.*include:_spf.google.com.*-all"$
Following the same process as before:
$ date ; ./search_txt_records.py < test_data.txt > test_google.output ;
date
Fri Jan 20 22:48:12 PST 2023
Sat Jan 21 18:53:06 PST 2023
This example obviously ran far faster: subtracting the times, we see it took 20 hrs, 4 minutes, 54 seconds (or 72,294 seconds).
$ wc -l test_google.output
14,603,386 test_google.output
That implies a rate of 14,603,386/72,294=202 FQDNS/second on average.
Extracting just unique effective 2nd-level domains, we get:
$ 2nd-level-dom-large < test_google.output | sort -u > test_google_output_uniqued.txt
$ wc -l test_google_output_uniqued.txt
532,451 test_google_output_uniqued.txt
That translates to a rate of 532,451/72,294=7.36 effective 2nd-level domains/second on average.
FAQs
a) What If There’s More Than a Million Results in Flexible Search or Standard Search?
The examples we’ve used in this blog don’t go beyond a million results for either Flexible Search queries or for followup Standard Search queries, even though DNSDB may have more results in either of those cases.
If required: we could request up to three additional “offset” queries after each initial query (to get a total of up to four million results in Flexible Search), and then ask for up to four million results for each of those four million Flexible Search results in Standard Search.
It’s unlikely that we’d ever actually need or use that many results, but frankly even the thought of potentially finding up to 4,000,000 * 4,000,000 = 16,000,000,000,000 (16 trillion) results is a bit overwhelming!
b) The Python3 API code example you use actually uses Python3 threading rather than Python3 multiprocessing. Wouldn’t true multiprocessing be faster, since it potentially uses all available cores, while Python3 threading is limited to just one core?
We’ve got a report coming out that explicitly considers and compares Python3 threading and Python3 multiprocessing for DNSDB API queries. At the risk of “ruining the surprise,” because we can only run a maximum of ten concurrent parallel streams, threading is actually as efficient as multiprocessing for this application on modern systems connecting to DNSDB services over the Internet.
Conclusion
DNS TXT records are extraordinarily flexible. While originally designed as a place for human-readable notes in DNS, two of the most important uses for DNS TXT records today are for email delivery management via SPF entries and domain ownership verification via control strings. The global nature of DNS does mean, however, that this information is available to any third party who is interested in looking for it.
Farsight DNSDB, being the leading repository of passive DNS data, contains TXT records observed from across the Internet. Using the DNSDB Scout web UX, our command line clients (dnsdbflex and dnsdbq), and the DNSDB API, we showed how you can perform a flexible search to find TXT records meeting a specific pattern and then pivot to find all related domains.
We hope you’ve found this an interesting exploration of searching DNS TXT records with DNSDB Flexible Search. Please contact us if you’d like to learn more!
Appendix I: 2nd-level-dom-large
$ cat /usr/local/bin/2nd-level-dom
#!/usr/bin/perl
use strict;
use warnings;
use IO::Socket::SSL::PublicSuffix;
my $pslfile = '/usr/local/share/public_suffix_list.dat';
my $ps = IO::Socket::SSL::PublicSuffix->from_file($pslfile);
my $line;
foreach $line (<>) {
chomp($line);
my $root_domain = $ps->public_suffix($line,1);
printf( "%s\n", $root_domain );
}Note: Get a copy of the Public Suffix List from https://publicsuffix.org/
Appendix II: search_txt_records.py
$ cat search_txt_records.py
#!/usr/local/bin/python3
""" search_for_dkim_records.py """
import json
import multiprocessing.dummy as mp
import os
from pathlib import Path
from signal import signal, SIGINT
import sys
from sys import exit, stdin
# https://requests.readthedocs.io/en/latest/
import requests
def get_api_key():
""" Retrieve the DNSDB API key """
api_key_file_path = os.path.join(str(Path.home()), ".dnsdb-apikey.txt")
try:
with open(api_key_file_path, encoding='UTF-8') as my_api_file:
val = my_api_file.readline().strip()
except FileNotFoundError:
exit("DNSDB API key should be in ~/.dnsdb-apikey.txt")
return val
def handler(_ , _2):
"""Stub routine to handle the user hitting ctrl-C"""
exit("\nUser hit ctrl-C -- exiting")
def flex_search_rdata(pattern):
""" Make Flexible Search for regex pattern in Rdata """
# hardcoded as TXT records only for this example
flex_url = "https://api.dnsdb.info/dnsdb/v2/regex/rdata/" + pattern + \
"/TXT?limit=1000000&time_after=-86400"
myheaders = {'X-API-Key': my_apikey, 'Accept': 'application/jsonl'}
r = requests.get(flex_url, headers=myheaders, timeout=3600)
flex_results = []
# Status Code 200 == Success
if r.status_code == 200:
stripped_results = remove_saf_entries(r.text)
for ahit in stripped_results:
myhit=json.loads(ahit)
if len(myhit) == 1:
rhs_raw_rdata = myhit['obj']['raw_rdata']
flex_results.append(rhs_raw_rdata)
return flex_results
else:
sys.stderr.write(pattern+" returned status code="+r.status_code+"\n")
def make_raw_rdata_query(raw_rdata):
""" Query right hand side for matching raw rdata from Flexible Search """
my_apikey = get_api_key()
for one_raw_hex in raw_rdata:
# we're hardcoding queries just for TXT records for this example
url = "https://api.dnsdb.info/dnsdb/v2/lookup/rdata/raw/" + \
one_raw_hex + "/TXT?limit=1000000&time_after=-86400"
myheaders = {'X-API-Key': my_apikey, 'Accept': 'application/jsonl'}
r = requests.get(url, headers=myheaders, timeout=3600)
# Status Code 200 == Success
if r.status_code == 200:
stripped_results = remove_saf_entries(r.text)
for myresults in stripped_results:
myresults_json_format = json.loads(myresults)
myrrname = myresults_json_format['obj']['rrname']
sys.stdout.write(myrrname+"\n")
sys.stdout.flush()
else:
sys.stderr.write(raw_rdata+" returned status code="+r.status_code+"\n")
def remove_saf_entries(mylist):
""" Remove the Streaming API Framing Records From the Results """
mylist2 = mylist.splitlines()
# Strip the streaming format bookend records
if mylist2[0] == '{"cond":"begin"}':
mylist2.pop(0)
if ((mylist2[-1] == '{"cond":"succeeded"}') or \
(mylist2[-1] == '{"cond":"limited","msg":"Result limit reached"}')):
mylist2.pop()
return mylist2
if __name__ == "__main__":
# Did you forget to pipe in the sites to check?
if stdin.isatty():
exit("Pipe in sites to check via stdin")
# handle ctrl-C interrupt cleanly
signal(SIGINT, handler)
my_apikey = get_api_key()
my_results = []
for line in stdin:
# find matching raw rdata in Flexible Search
raw_right_hand_side_data = flex_search_rdata(line.rstrip())
my_results.append(raw_right_hand_side_data)
with mp.Pool() as p:
p.map(make_raw_rdata_query, my_results, chunksize=10)
p.close()
p.join()


